While most tools for MRE are staightforward, some of them require time, patience, and skills to show the full power. For static analysis, this means IDA; for dynamic analysis, it is OllyDbg (and WinDbg for Windows kernel debugging). In this post, we will play disassembly code heavily with both tools. Remember – the key point of MRE is not to fully understand every line of disassembly, but rather to construct a big picture of the malware in a high-level programming language, e.g., C/C++. If you have a Hex-Rays decompiler already, use it to make your life easier. Otherwise, read this post.
0. Report header
Apr 11, 2016. GNV, FL.
1. Download the malware – play with your own risk!
Git clone my git repo (https://github.com/daveti/mre) and copy the malware_g.7z into the Windows VM. NOTE: there is not password protection for this malware.
2. Summary
This malware G and the accompanied jellydll.dll are a proof-of-concept GPU-based rootkit called JellyCuda (https://github.com/x0r1/WIN_JELLY). It leverages the Nvidia GPU non-volatile memory to hide the malicious jellydll.dll and make it persistent without being detected by scanning the hard disk of the host machine. When the host is infected by the JellyCuda the first time, it loads the jellydll.dll into the GPU memory, creates a file called jellyboot.vbs in the startup folder and writes itself into the pre-formated VBscript, making sure that the malware would run every time when the machine is booted, and finally the jellydll.dll is removed. After the machine is rebooted, the malware looks for the jellydll.dll. If the dll file is still available, the malware would repeat the previous procedure to hide the malicious DLL file in the GPU memory. Otherwise, the malware reads the GPU memory, finds the memory block containing the jellydll.dll contents, reconstructs the DLL file in the memory, replaces the current process memory with the contents of the DLL, and finally calls the DllMain() entry function of the jellydll.dll, which simply prints out warnings of the existence of the GPU RAT.
Since this is a proof-of-concept malware, specific signatures or remediations for this malware may not be interesting or useful. However, JellyCuda does give us some hints to think about GPU-based rootkit in general:
- Calls to CUDA/OpenCL – normal applications usually do not deal with GPU directly.
- cuMemAlloc, cuMemcpyHtoD, cuMemcpyDtoH (or the OpenCL equivalents) – this means there is memory block transmission between the main RAM and the GPU memory.
- New file created – either the registry and/or the startup folder or the prefetch folder may be changed to include the malware itself, making sure it persistent across rebooting.
To remove JellyCuda from the system, one needs to clean the residency in the GPU memory at first, position the malware itself based on the modified registry/startup/prefetch, and remove it. The good news is that my Avast is able to recognize the JellyCuda as malware when I tried to copy it into the VM for analysis on my Mac.
NOTE: this report focuses on IDA and OllyDbg analysis, rather than other straight-forward tools. IDA analysis shows the complete picture of the malware, and OllyDbg digs into the malicious payload (jellydll.dll), which could not be analyzed by IDA.
3. Static Analysis
No, though PEiD shows a packer named Pelles C for this malware, but it is the compiler which compiles the binary, not the packer.

And nothing found for the accompanied dll:
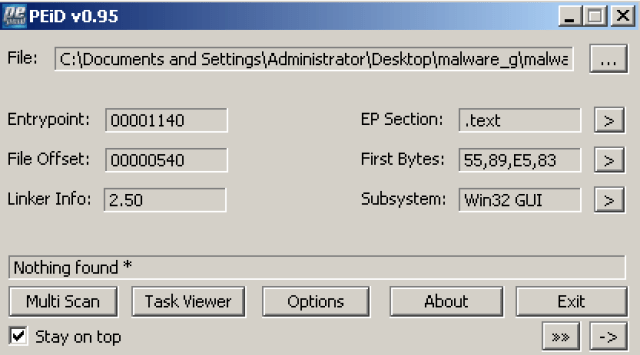
Malware_g.exe: 2015/05/09.

Jellydll.dll: 2015/05/09

Malware_g.exe: PEiD thinks it is a Win32 GUI and PEview thinks the same way.

jellydll.dll: PEiD reports it as Win32 GUI and PEview agrees.

malware_g.exe:
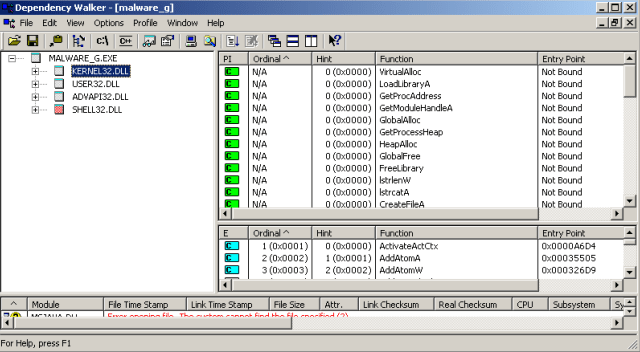
Kernel32.dll:
File manipulation:
CreateFile, WriteFile, CloseHandle, GetFileSize, ReadFile, DeleteFile, GetFileAttributes, GetFileType, GetStdHandle, DuplicateHandle, SetHandleCount,
Memory manipulation:
VirtualAlloc, GlobalAlloc, HeapAlloc, GlobalFree, HeapCreate, HeapDestroy, HeapReAlloc, HeapFree, HeapSize, HeapValidate, VritualQuery
Process manipulation:
GetProcAddress, GetModuleHandle, GetProcessHeap, GetModuleFileName, GetCurrentProcess, ExitProcess,
Library manipulation:
LoadLibrary, FreeLibrary,
Others:
Strlen, strcat, GetLastError, GetStartupInfo, RtlUnwind, GetSystemTimeAsFileTime, GetCommandLine, GetEnvironmentStrings, FreeEnvironmentStrings, UnhandledExceptionFilter, WideCharToMultiByte, SetConsoleCtrlHandler
User32.dll:
MessageBox, wsprintf, ExitWindowsEx
Advapi32.dll:
OpenProcessToken, LookupPrivilegeValue, AdjustTokenPrivileges
Shell32.dll:
SHGetKnownFolderPath
jellydll.dll:

User32.dll:
MessageBox
Kernel32.dll:
File manipulation:
GetFileType, GetStdHandle, DuplicateHandle, SetHandleCount,
Memory manipulation:
VirtualAlloc, VirtualFree, HeapCreate, HeapDestroy, HeapReAlloc, HeapFree, HeapSize, HeapValidate, VritualQuery
Process manipulation:
GetCurrentProcess, ExitProcess,
Others:
GetStartupInfo, GetSystemTimeAsFileTime, GetCommandLine, GetModuleFileName, GetEnvironmentStrings, FreeEnvironmentStrings
malware_g.exe:
IP: N/A
URL: N/A
Process: svchost
File:
Jellyboot.vbs, malware_g.exe
Files generated by the compiler:

Commands/Scripts:

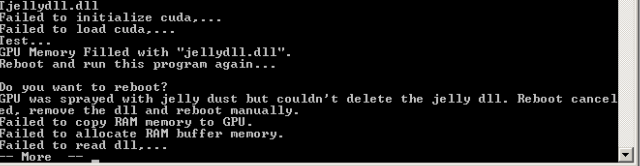
Error handling:
CUDA:


Interesting:
NtFlushInstructionCache,

Functions:

Malware_g.dll:
Interesting:


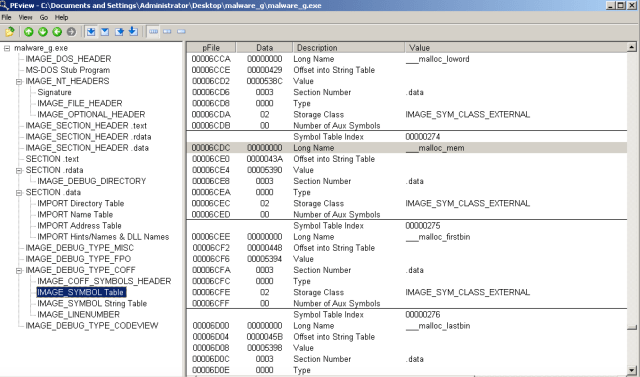
malware_g.exe: there are 3 sections in total
.text: it looks like there is code in it.
.rdata: Warning strings, windows commands, CUDA functions, and interesting stuffs
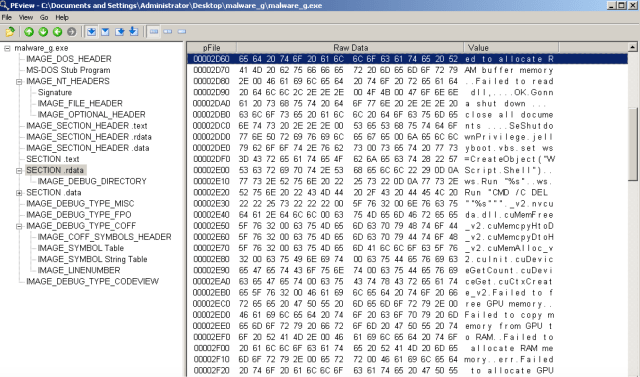
.data: IAT, and a bunch of debug sections, including COFF

Jellydll.dll: there are 4 sections.
.text: normal code
.rdata: malware writer’s kind reminder
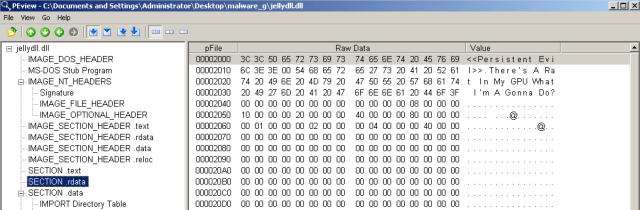
.data: IAT

.reloc: relocation table
(g) Resource
ResourceHacker found nothing for either the malware_g.exe or jellydll.dll.
(h) IDA Pro
Malware_g.exe:
The first entry function of malware_g.exe is WinMainCRTStartup(), which is generated by the Pelles C compiler for Windows.

It sets up an exception handler, which calls RtlUnwind(), which is usually generated by the compiler for try/except. It then moves to allocate space on the heap using HeapCreate() called by __bheapinit(). If failed, then exit. Otherwise, system setting up continues.


If everything is still good, we reach the second entry function WinMain(), which is the real function implemented by the malware.

The first thing WinMain() tries to do is to call LoadCuda().

If the loading is failed, the malware exits. Otherwise, it continues with a call to dword_40595C, dword_405958, dword_405954, and jc. Since all these are indirect calls, we need to figure out what these memory address are by looking into the LoadCuda().

As its name implies, LoadCuda() starts with loading nvcuda.dll using LoadLibrary(), and exits if the loading fails.

When nvcuda.dll is successfully loaded, memory address jc is loaded into %eax and then the local variable lpAddress. Looking at that memory address, we realize the connections among all those memory addresses. Jc is the start address of a struct with address 0x405950, and dword_405954, dword_405958, dword_40595C, …, dword_40596C are the following members of the struct. Since all members are dword (4 bytes) and called by the call instruction, this jc struct contains a bunch of function pointers.


Once jc is loaded into lpAddress, a loop starts on szFuncNames array. For each name in szFuncNames, GetProcAddress() is called with the library handle returned by LoadLibrary() and the name. The return value is assigned to the current value of lpAddress.

Looking into the szFuncNames, we see the CUDA functions we have seen in the strings.

Once LoadCuda() is done. Struct jc is initialized with all these CUDA functions in order. So back to the WinMain(), after LoadCuda() is successfully returned, cuInit(), cuDeviceGetCount(), cuDeviceGet(), cuCtxCreate_v2() are called one by one. Any call failure would free the loaded CUDA library and exit the malware. When CUDA is successfully initialized, GetFileAttributes() is called with jellydll.dll and the return value is checked against 0xffffffff (-1), which is INVALID_FILE_ATTRIBUTES. GetLastError() is called and the return value is checked against 2, which is ERROR_FILE_NOT_FOUND. When both errors happen, SearchJellyDustOnGPU() is called; otherwise, SprayJellyDustToGPU() is called. Then FreeLibrary() is called and WinMain() returns.

SearchJellyDustOnGPU() calls AllocateGPUMemory() at first, which calls dword_405960, which is essentially the 5th member of struct jc – cuMemAlloc_v2().

If AllocateGPUMemory() failed, SearchJellyDustOnGPU() would exit. Otherwise, it continues calling GlobalAlloc(), dword_405964 (cuMemcpyDtoH_v2()), dword_40596C (cuMemFree_v2()), which copies the GPU into the host memory. Note that the copied memory size is expected to >= 0x1000C (65548) bytes.

The copied memory is then examined against a number 0x5DAB355 in a loop.

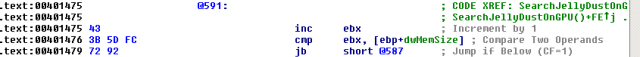
If the memory blocks starts with the magic number, and some checkings are passed, and GetDustCheckSum() is passed as well, we hit the core of this SearchJellyDustOnGPU() – GetProcessHeap(), HeapAlloc(), and ExecuteJellyDust(). Note that the ‘rep movsb’ copies the memory block we found with offset 0xC into a local variable lpvDust, which is then passed into ExecuteJellyDust().

The ExecuteJellyDust() function calls VirtualAlloc(), LoadLibrary(), and GetProcAddress() in a big loop. Based on the naming of local variables involved – pImport and pRelocBase, one can guess that this loop is used to reconstruct a library from the memory block. Finally, ExecuteJellyDust() loads ntdll.dll and calls NtFlushInstructionCache(), which parameters (-1, 0, 0), which is undocumented, and clears the old code in the cache. Finally, an indirect call to %eax is made with parameters (lpvTarget, 1, 0). Note that %eax is derived from pNt with offset 0x28, which is the offset of DllMain() against the PE signature. So, we know that final call is to call the entry function of the library created in the fly before. Now the question is what is that library?

The last function we haven’t looked at is SprayJellyDustToGPU(), which is called when the malware is able to find the jellydll.dll. The only parameter of this function is “jellydll.dll”. First, it calls CreateFile() to open jellydll.dll, and GetFileSize(). Then GetProcessHeap() and HeapAlloc() are called to allocate enough memory for jellydll.dll, which is then read into the memory via ReadFile(). AllocateGPUMemory() is called after followed by GetDustCheckSum() and GlobalAlloc(). Note that the magic number 0x5DAB355 is added ahead of the memory block of jellydll.dll.

The JellyDust (magic number + tweak(jellydll.dll)) is then copied into the memory allocated by the GlobalAlloc(), and later copied into the GPU memory via dword_405968 (cuMemcpyHtoD_v2()).

At last, file jellydll.dll is closed and deleted via CloseHandle() and DeleteFile(), before the Reboot() is called, which is the last piece of the malware_g.exe puzzle. This function calls SHGetKnownFolderPath() to open _FOLDERDIR_Startup, which is %APPDATA%\Microsoft\Windows\Start Menu\Programs\StartUp.

The startup path is then converted from wide chars into multiple bytes using wcstombs(), appended with byte 0x5C (‘\”), and null terminated.

Then file jellyboot.vbs is created under than startup direction.

After the new file is created, GetModuleFileName() is called to get the file path of the malware_g.exe itself. The jellyboot.vbs file then is written via WriteFile() with command lines formated by wsprintf() using the file path of the malware itself, and finally closed via CloseHandle(). The command lines are used to create a COM object using VBscript to run the malware itself and then remove itself.

The last thing Reboot() does is to call GetCurrentProcess(), OpenProcessToken(), LookupPrivilegeValue(), and AdjustTokenPrivileges() to gain the permission to reboot the machine using ExitWindows().

Jellydll.dll:
Now we know that jellydll.dll is the RAT, and the DllMain() entry function would be executed by the malware_g.exe. However, IDA screws the analysis of this library. The dll entry function tries to call sub_10001030, which is the address in the .rdata section.


4. Dynamic Analysis
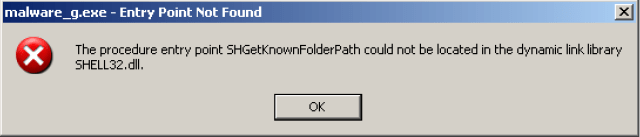
Malware_g.exe
We are not able to run malware_g.exe, not only because of the CUDA requirement, but also the fact that below procedure could not be located. Why? This function is only available above Windows Vista.
Jellydll.dll:
To see what the heck jellydll.dll is doing in its DllMain() entry function, we load jellydll.dll into OllyDbg, which asks if we want to load LoadDLL.exe to run the library. After yes, we finally see the RAT.

Then we break at the new module loading time and find the exact DllMain entry function, which is at 0x7C901187.

Then we break at the DllMain() function to examine the stack. %esp is 0x0006F8AC, and %ebp is 0x0006F8C4. The first parameter of the function is at the top of the stack, which is address 0x0006F8AC. The second parameter is address 0x0006F8B0. The third parameter is address 0x0006F8B4. The function call is ss:[ebp+8], which is address 0x0006F8CC.
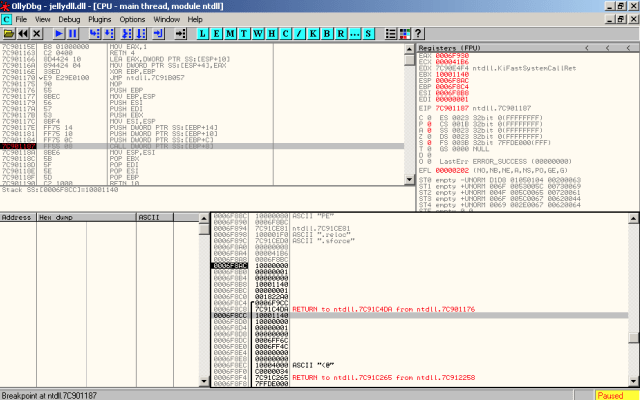
Moving on to look back at the stack, we have:
First parameter (hinstDLL) – 0x0006F8AC: 0x10000000 – should be the handle to the loaddll.exe itself.
Second parameter (fdwReason) – 0x0006F8B0: 0x00000001 – that is the REASON code DLL_PROCESS_ATTACH.
Third parameter (lpvReserved) – 0x0006F8B4: 0x00000000 – NULL for dynamic loads.
Function call – 0x0006F8CC: 0x10001140 – that is the correct address of DllEntryPoint() shown in IDA.
There we go, let us step into the DllMain(). The real function call in the DLL entry is at address 0x1000117E, with an instruction “call 10001000”. So break at this line again and examine the stack.
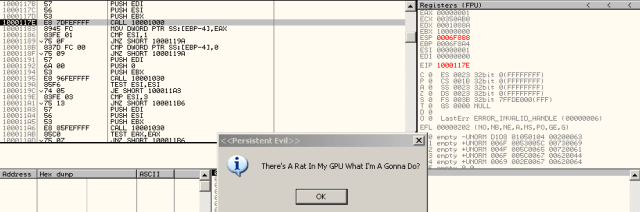
Now interesting thing happens. When we try to set a breakpoint at the address, OllyDbg tells us that we are looking at the code in the data section rather than the code section, which may explains why IDA screws. Anyway, set the breakpoint and step into.

We finally see the final function called in the DllMain() of the jellydll.dll. It is a call to MessageBox with the capital string and the RAT string.

5. Indicators of compromise
Since this is a proof-of-concept of GPU-based malware, it is easy to know the machine is compromised when the warning window shows up. In reality, the indicator could be non-trivial to find, depending on the implementation of the GPU payload (jellydll.dll). If it is a rootkit, it may stay in the machine for a long time without detection, and even AV may not help. If it is a RAT, we may be able to find unfamiliar socket connections with outside. If it is a ransomware, we know when we know.
6. Disinfection and remedies
It is not clear so far what the best solution would be for GPU-based malware (and I am going to dig deeper to see if there would be a paper potential). Since current prototypes of GPU-based malware require a ‘helper’ in the host system to make it work, Intel does not think it would be threat (http://www.securityweek.com/gpu-malware-not-difficult-detect-intel-security). On the other hand, my Avast on Mac is able to detect the JellyCuda when I tried to move it into the VM for analysis. As far as I can think of now is a system tool/mechanism to look into the GPU memory for malware detection just like AV does on the host machine. We may also reconsider the access control for the GPU from the security point. Yeah, I am talking about the pitch of a potential paper trying to defense GPU malware. Will see how it goes:)