I took a “Malware Reverse Engineering (MRE)” class last semeter and it was fun to me, partially because I was not a Windows person, though I am still not. What seems ridiculous to me is how trivial one can write into any process on Windows XP, which was apparently designed for malware! Regardless of all those Windows craps, this post is to share a general working flow of malware reverse engineering on Windows (XP) platform, and the corresponding tools. Note that this report has no way to be a good one. Instead, this was my first trial and I intended to put as much information as possible. If you are interested in MRE or wants a job for that, do buy this book (https://www.nostarch.com/malware) and give it a complete read. Have fun and stick with Linux~
0. Report header
Feb 12, 2016, GNV FL.
1. Download the malware – play with your own risk!
All the malware samples can be found on my github (https://github.com/daveti/mre). All malware binaries are compressed by 7Zip with password “malware” protection. This post is about the first malware/ransomeware uploaded. Before you start, make sure you have a Windows VM (KVM/VirtualBox/VMware) ready with networking disconnected from the host machine.
2. Summary
This malware is a kind of ransomware. The IP/domain of the networking is encoded instead of plain text. The encryption routine is also a DIY method without calling existing crypto libraries. Most imports are ReadFile/CreateFile/DeleteFile. 2 new entries are added into the registry, and one of them is the malware itself. All *.doc, *.txt, *.jpg, and etc. under C: are encrypted. A DNS query is also triggered for domain “time.windows.com”. The file “CryptoLogFile.txt” may be used to detect this malware, since it is created at first to log all the files encrypted. “time.windows.com” seems not a helpful signature, since it is a valid domain.
3. Static analysis
- Is it packed?
Seems not.
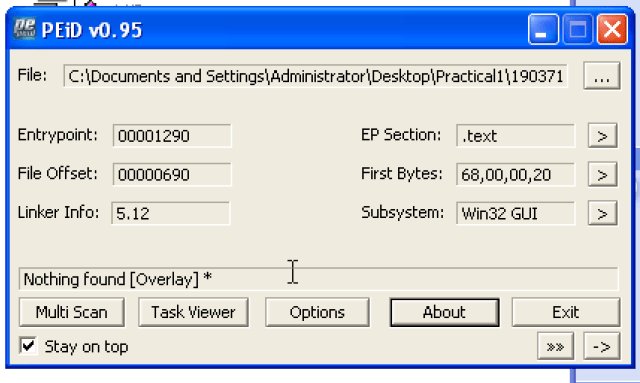
PEiD: Nothing Found (but shows Win32 GUI as its subsystem).

PEview: A lot of imports can be found.
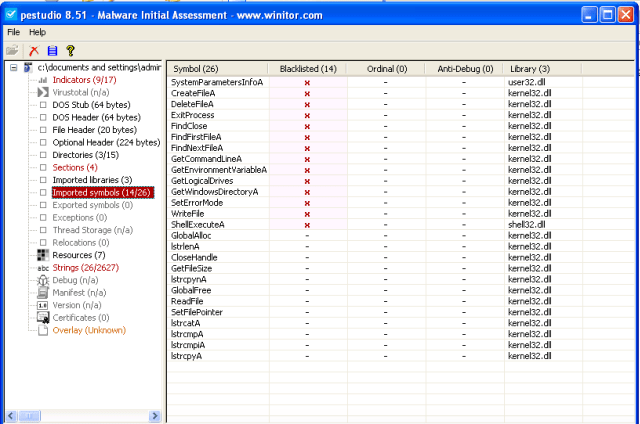
pestudio: same as PEview
If PEiD is able to detect packer, it would provide the information of the packer, which can be used to find the unpacker; If PEiD fails, we have to refer to PEview/pestudio, investigating the imports and section contents manually.
- Compilation data?
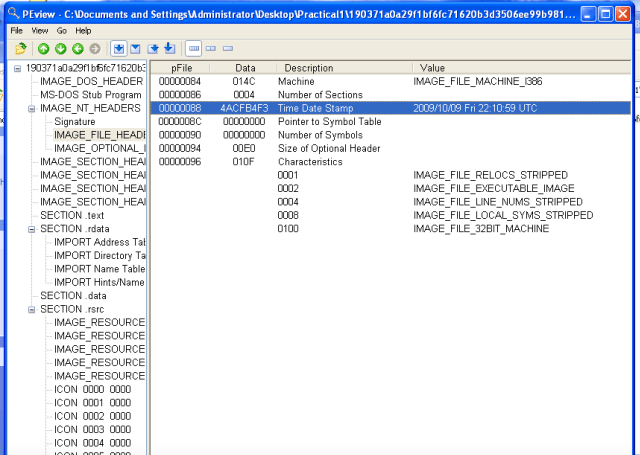
PEview: 2009/10/09.
- GUI or CLI?
Seems CLI.
PEview: There is no GUI related functions or DLL found in the text section.

Depends: It only depends on user32.dll, kernel32.dll, and shell32.dll.
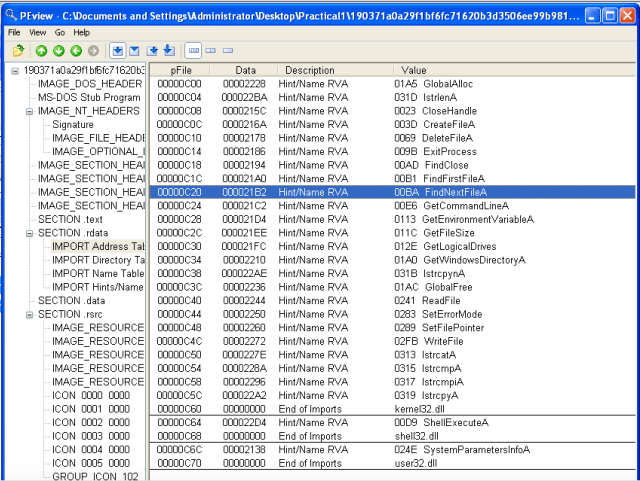
- Imports?
PEview: file related operations (CreateFile, DeleteFile, FindFile, ReadFile, WriteFile), a bunch of ‘get’ functions (GetCommandLine, GetEnvironmentVariable, GetFileSize, GetLogicalDrives, GetWindowsDirectory), and some string operations (lstrcat, lstrcmp, lstrcpy). A wild guess would be this malware goes into the Windows directory, removes the target files, and also creates some new files.
- Strings?
strings2:
IP: NA
URL: NA
Process: NA
File: user32.dll, kernel32.dll, shell32.dll, CryptLogFile.txt, wallpaper.bmp, .txt, .doc, .xls, .db, .mp3, .waw, .jpg, .rtf, .pdf, .zip,

pestudio:

- Sections and contents?
PEview: text seems OK; rdata contains imports address table, directory table, name table, as shown in (d); data contains 2 interesting file names (CryptLogFile.txt, wallpaper.bmp); rsrc contains some icons, which seem fine.

ResourceHacker: rsrc section looks no code embedded.
IDA Pro
- The first file created
There are 3 subroutines and main calling CreateFile:
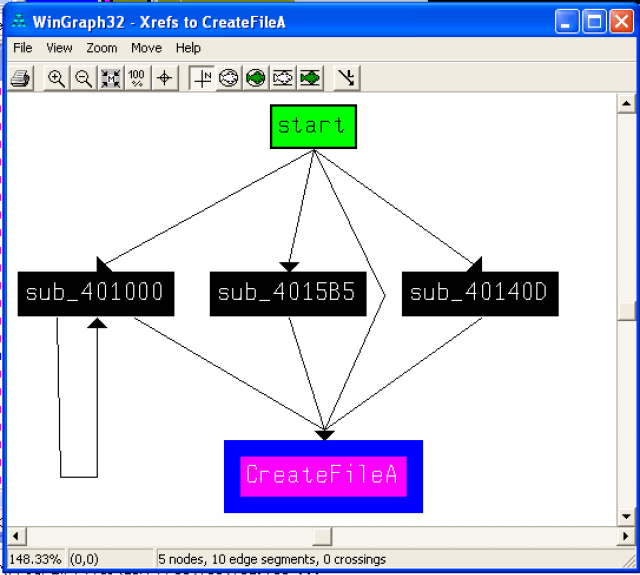

The main function prepares the file name to be “c:\windows\CryptoLogFile.txt”,
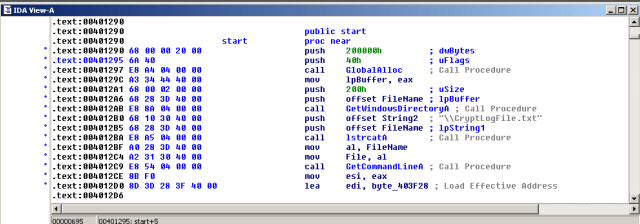
and then save it at byte_403F28 after preprocessing – removing the char 22h,

and then call sub_4015B5, which calls CreateFile the first time, which then creates the file using the filename at byte_403F28, which is the CryptoLogFile.txt.

- dword 0xCA6B93C9
The DIY encryption routine uses this table to look up for a value, then XOR with the original value to achieve the encryption. If the encryption was PKI, then this secret data buffer could hold keys, .e.g., private key can be used to encrypt, while the public key would be sent to the attacker asking for ransom.
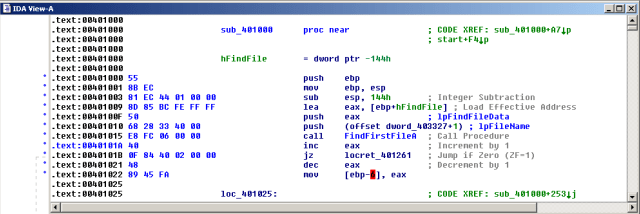
- sub_401000
This routine starts with FindFirstFileA to find a specific file, and returns if the search fails (locret_401261), and keeps looping till all the target files have been gone thru.
- sub_40140D
I would try to name it as – read the file, encrypt it into a new file, and remove the original file.

It also calls the shell del command to remove the file:

- sub_401263
I would rename it as – DIY encryption routine, especially after I saw the operations like:
lodsb
xor eax, the_secret_look_up_table[edx]
stosb

4. Dynamic analysis
Preparement:
REMnux: start inetsim

Windows:
start apateDNS
start Process Explorer
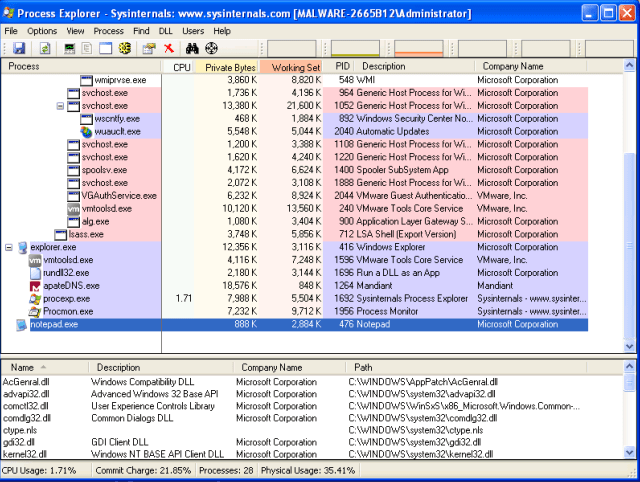
start Procmon (then pause and clear)

start RegShot (the 1st shot)

Unpause the Procmon; Execute the malware; Pause the Procmon (seems it got hang every time…)

Take 2nd RegShot
- Interesting behaviors that occur after the malware has executed.
- Machines and services the malware attempts to contact by IP or domain or host name.

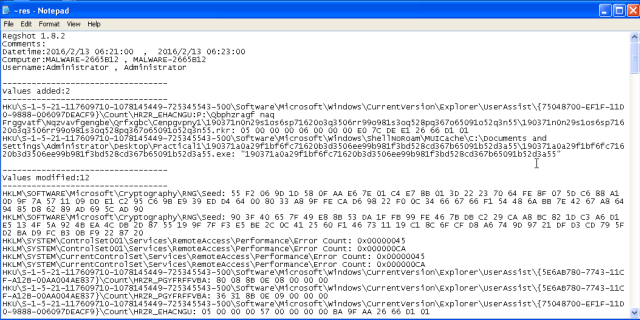
- Registry keys created/modified by the malware
- Files created/modified by the malware
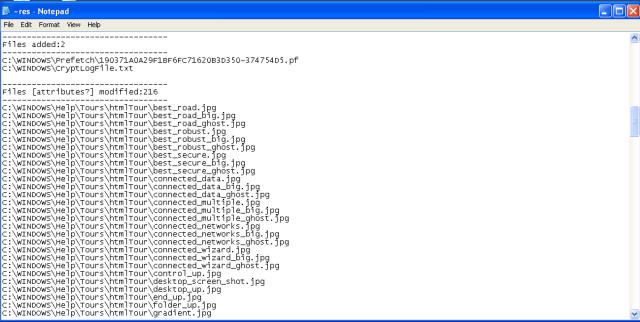
There are also files encrypted outside the windows directory, e.g., the Dynamic Analysis directory on the desktop. Since I was scanning the dir only under c:\windows, these files are not shown in RegShot. However, CryptoLogFile lists all the encrypted files (how nice is that).
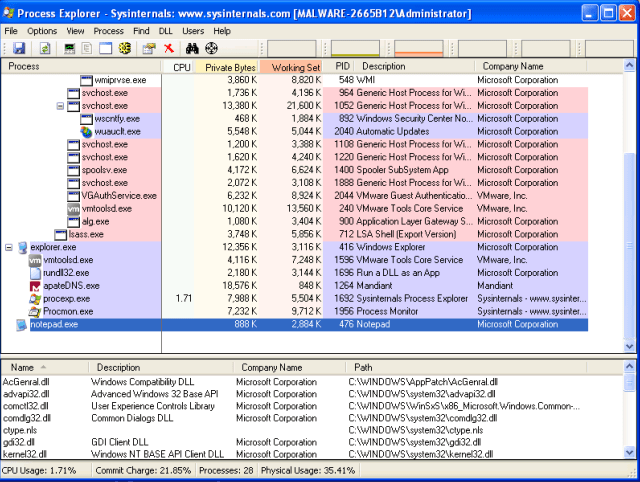
- Processes started by the malware
Notepad, and maybe else (Procmon stuck when pause…)
5. Indicators of compromise
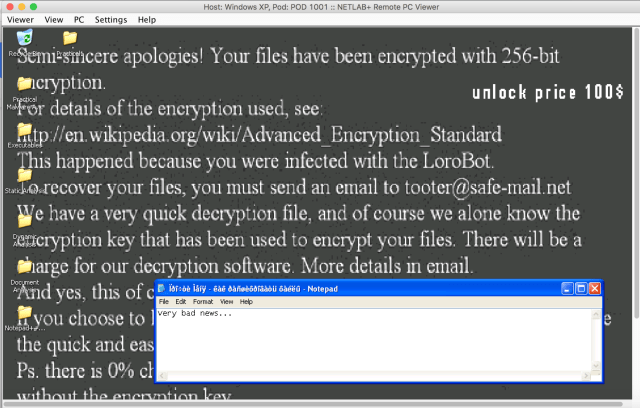
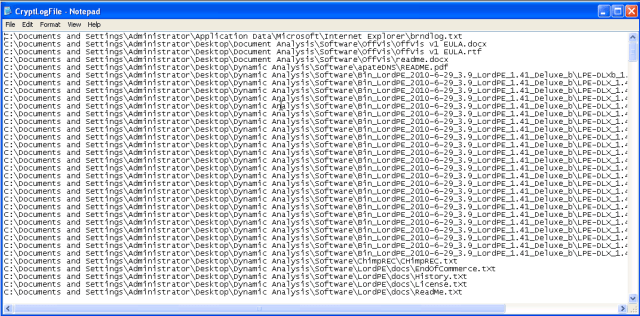
A lot of files have been encrypted, as listed in CryptoLogFile.txt. For example, one of the README.txt looks like below. And, for sure, comes the “new” wallpaper with introduction to ransomware, and ways to pay the ransom.

6. Disinfection and remedies
To make sure this ransomware will not start again, need to do a clean up in the registry. If there is a data backup (there should be), or a system snapshot, do a recover – yeah, problem solved. If there is no data backup, and I am able to decrypt the encryption routine (DIY crypto could be vulnerable comparing to other common crypto methods and implementations), then it is time to learn maths and assembly. Otherwise, which may be the most common way, pay the ransom.